
OVH : Hébergement mutualisé en RADE le 3/11/2017 et PANNE GÉNÉRALE le 9/11/2017

Hier une nouvelle méga-panne sur les serveurs des hébergements mutualisés d’OVH a rendu injoignable plusieurs dizaines de milliers, voire plus, de sites en France
- Mise à jour : 14/11/2017 – OVH semble(rait) avoir réglé tous ses problèmes techniques
- Mise à jour : 9/11/2017 – Nouvelle Méga-Panne mais cette fois-ci GÉNÉRALE
- Mise à jour : 5/11/2017 – Serveurs P19 / All custers – Front-end servers issue
OVH, fournisseur mondial de cloud hyper-évolutif et n° 1 en Europe, n’en est pas à son coup d’essai. En Juin-Juillet dernier, plus de 50.000 sites Web qui ont souscrit à une offre d’hébergement mutualisé, ont été affectés par une méga-panne chez OVH. Cet incident avait laissé les sites inaccessibles pendant plusieurs heures. Une crise d’envergure pour l’hébergeur roubaisien qui n’avait pas connu de pareil incident depuis 2006.
- Mutualisé : OVH s’explique sur la panne de 50.000 sites et annonce un geste commercial – Next Inpact le 7/07/2017
- Mutualisé d’OVH : importante panne, communication floue, clients dans l’expectative – Next Inpact le 3/07/2017
- Méga-panne chez OVH : plus de 50.000 sites Web dans le noir en pleines soldes – ZDNet le 30/06/2017
- OVH : hausse de prix, manager v6 « pleinement fonctionnel » et renouvellement automatique – Next Inpact le 15/12/2015
- Un hébergement Web mutualisé plus intelligent et plus dynamique – OVH le 17/10/2013
Une introduction au concept de mutualisation de l’hébergement Web chez OVH
La direction d’OVH avait promis, juré, craché qu’après la méga-panne de juin-juillet 2017 elle mettrait en place une équipe dédiée à la communication en cas de crise. Mais en novembre 2017 nous devons constater que ses belles déclarations d’intention n’ont pas été suivies d’effet. Les clients OVH doivent toujours aller à la pêche aux informations !
♦ 3/11/2017 : OVH remet le couvert !
Hier, mon site Web LINUX ♥ ROUEN ♥ Normandie | Libriste ♥ seinomarin (76) affichait à chaque tentative de connexion – soit Le délai d’attente est dépassé – soit La connexion n’est pas sécurisée – soit Une page blanche avec indication de tentative de connexion en boucle. Ce n’était pas très accueillant pour les visiteurs du site.
Autant pour un site non-marchand on peut vivre avec cela, autant pour un site marchand c’est la catastrophe tant du point de vue de l’image de marque que du chiffre d’affaires.
Après les premières investigations effectuées, il m’est devenu clair que le problème ne venait pas de mon site mais bien de son hébergeur OVH.
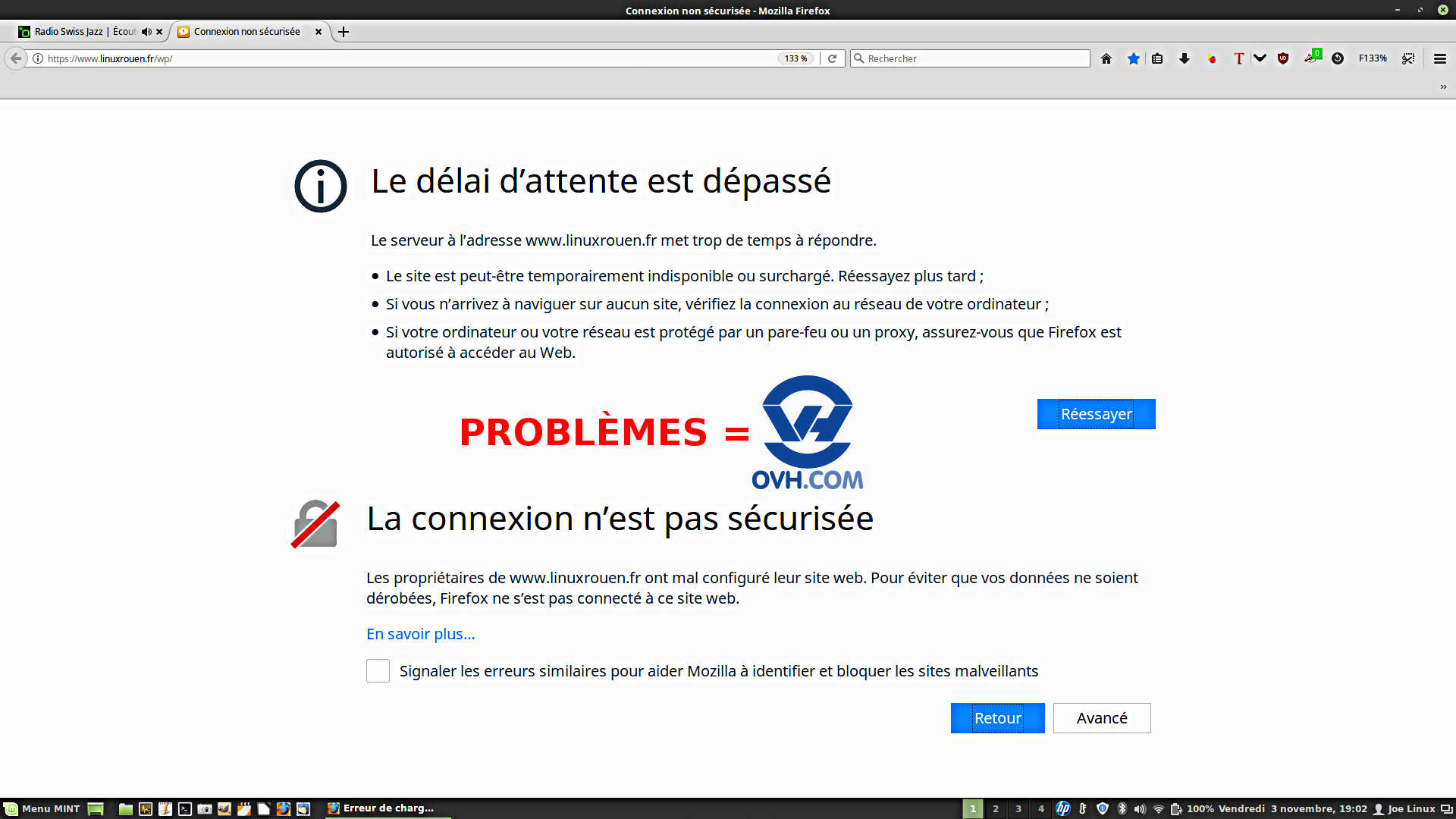
Hébergement mutualisé d’OVH : Impossibilité de se connecter au site www.linuxrouen.fr une bonne partie de l’après-midi du 3/11/2017 !
En poussant mes investigations plus loin je me rendis compte que la majorité des grandes agglomérations françaises (Paris jusqu’à Rouen et Le Havre, Lille, Lyon, Marseille, Nice, Toulouse, etc.) étaient affectées par ce méga-problème d’indisponibilité des serveurs mutualisés d’OVH.
Devant l’ampleur de l’incident, c’est comme cela que chez OVH on nomme pudiquement un méga-problème, un ticket #28134 a été ouvert à 15H54 alors que les remontées du terrain avaient débuté près d’une heure plus tôt. Le détail de ce ticket indiquait : « Catégorie : P19 / All clusters. Un problème sur les load-balancers frontaux perturbe l’accès à l’ensemble des clusters de l’Hébergement Web. Nos équipes y travaillent. ».
Pour mémoire : Pour accueillir les plus de 3 millions de sites Web en hébergement mutualisé OVH utilise 2 datacentres : le DC historique à Paris (P19) et le nouveau DC à Gravelines (GRA1).
Puis, plus tard dans l’après-midi des précisions supplémentaires étaient ajoutées :
– Depuis 15:30, les répartiteurs de charge de MUTUALISATION subissent une forte charge rendant difficile l’accès à vos sites web. Toutes les équipes concernées travaillent à la résolution de cet incident (Mutu, IPLB, VAC, Network, etc.).
– Les problèmes de certificats SSL sont aussi liés à cet incident.
– L’envoi de mails en sortie des hébergements web est aussi perturbé.
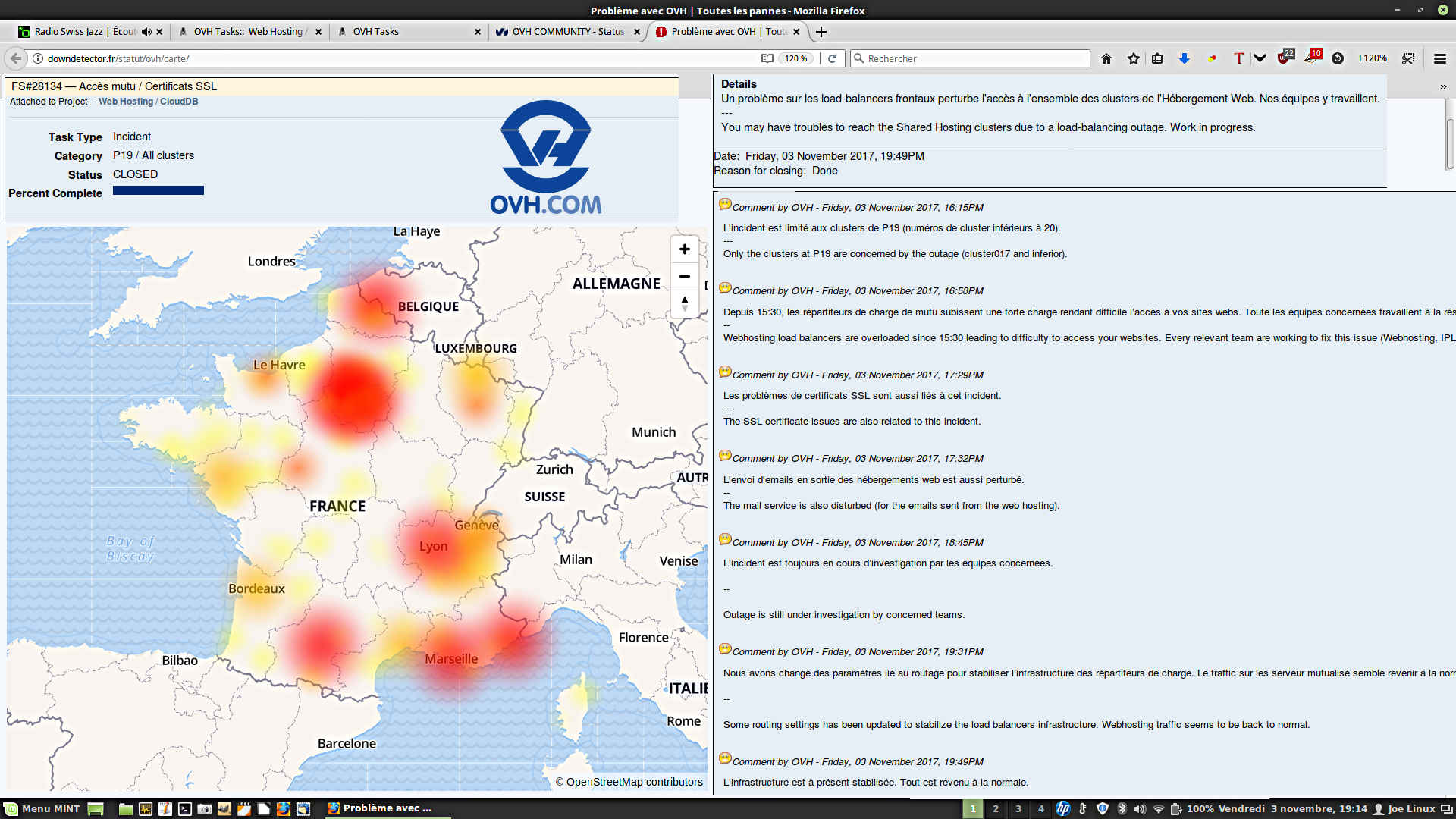
Hébergement mutualisé d’OVH : la majorité de la France en rade l’après-midi du 3/11/2017 !
L’après-midi… la Seine continuant de s’écouler lentement mais sûrement sous les ponts de Rouen… aucune amélioration de la situation n’était en vue chez OVH.
Puis, en fin d’après-midi de nouvelles précisions d’OVH tombent :
– 18:45 : L’incident est toujours en cours d’investigation par les équipes concernées.
– 19:31 : Nous avons changé des paramètres liés au routage pour stabiliser l’infrastructure des répartiteurs de charge. Le trafic sur les serveurs mutualisés semble revenir à la normale.
– 19:49 : L’infrastructure est à présent stabilisée. Tout est revenu à la normale.
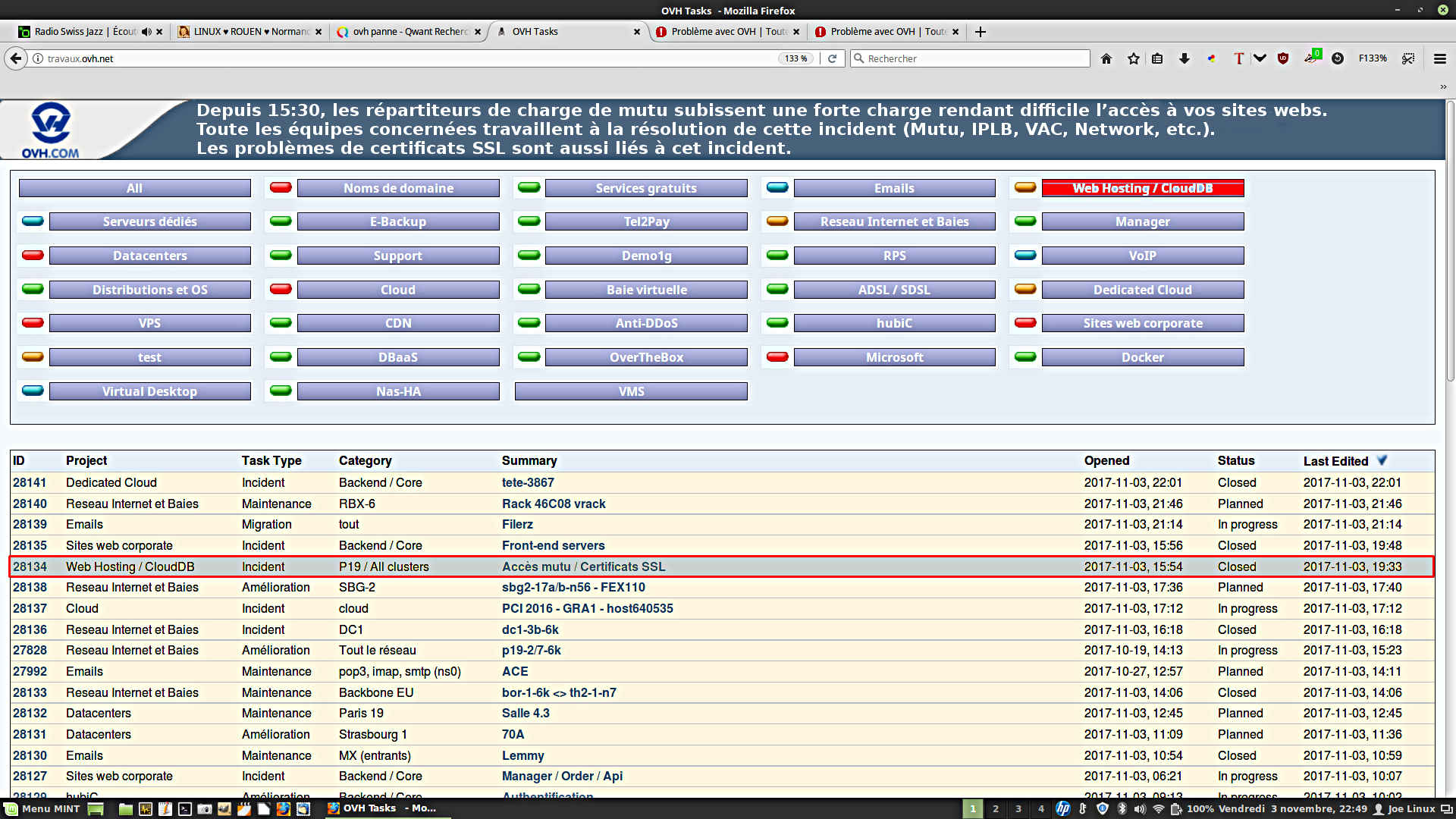
Hébergement mutualisé d’OVH : Incident ID #28134 ouvert pendant près de 4 heures le 3/11/2017 !
Vérification faite, mon site Web était bien de nouveau accessible (partie visiteur et administration) et la carte de France des pannes d’OVH ci-dessus voyait son niveau de rouge diminuer pour passer au jaune et vers 20h30 tout semblait être revenu à la normale.
OVH a clôturé son ticket #28134 le 3/11/2017 à 19H33.
- OVH : des soucis de load-balancing sur son versant hébergement mutualisé – Silicon le 4/11/2017
♦ Quels enseignements tirer de ce méga-problème chez l’hébergeur OVH ?
- Des méga-pannes peuvent se produire même chez OVH et même plusieurs fois par an.
- Le message initial d’OVH « Les répartiteurs de charge de MUTUALISATION subissent une forte charge rendant difficile l’accès à vos sites web. » laissait à penser que cette méga-panne était d’origine externe à la société, comme une attaque de ses serveurs.
- Néanmoins, le message final d’OVH « Nous avons changé des paramètres liés au routage pour stabiliser l’infrastructure des répartiteurs de charge. » laisse plutôt à penser que ce méga-problème était bien interne à OVH, qui d’ailleurs ne communique jamais vraiment sur le détail des causes et solutions réelles d’un incident clos.
- Que OVH doit informer automatiquement par mail ses clients impactés par les incidents majeurs survenant sur ses serveurs, ce qui aujourd’hui n’existe toujours pas.
- Que OVH doit nettement améliorer l’affichage que les internautes voient sur leur écran quand un site n’est pas joignable du fait d’OVH, par exemple en affichant un message « Site fonctionnel mais indisponible du fait de l’hébergeur » en lieu et place des deux messages en début d’article.
- Que OVH doit améliorer la structure et la documentation de son site OVH Travaux – Tous les travaux en cours sur les infras OVH afin de mieux aider les webmestres à trouver rapidement l’information recherchée en cas de méga-bogues sur l’infrastructure OVH.
Recommandation : Un site marchand, même petit, ne devrait jamais utiliser un hébergement mutualisé pour son site Web. Vouloir faire une économie de quelques euros à quelques dizaines d’euros par mois sur son abonnement peut en fin de compte vous coûter beaucoup-beaucoup plus cher. Qui dit site marchand dit obligatoirement hébergement professionnel (non mutualisé). Tous les hébergeurs, dont OVH, proposent de multiples offres (OVH min. Performance 1) correspondant aux besoins de chacun.
- OVH et ses clients devront tirer les leçons de la panne qui a plongé dans le noir 50.000 sites web – LeMagIt le 3/07/2017
« Des leçons à tirer, pour OVH comme pour certains de ses clients… Ces clients devraient dès maintenant se poser la question de savoir si un hébergement vendu entre 1,5 et 6 € HT / mois, sans aucune garantie de disponibilité ni de SLA (accord de niveau de service), était la meilleure option pour leur précieux site d’e-commerce… »
♦ 4/11/207 : Les problèmes perdurent encore pour beaucoup de sites Web hébergés chez OVH !
Par exemple, mon accès Administrateur et/ou le changement de tâche à l’intérieur du Tableau de bord (Dashboard) de WordPress plantent régulièrement.
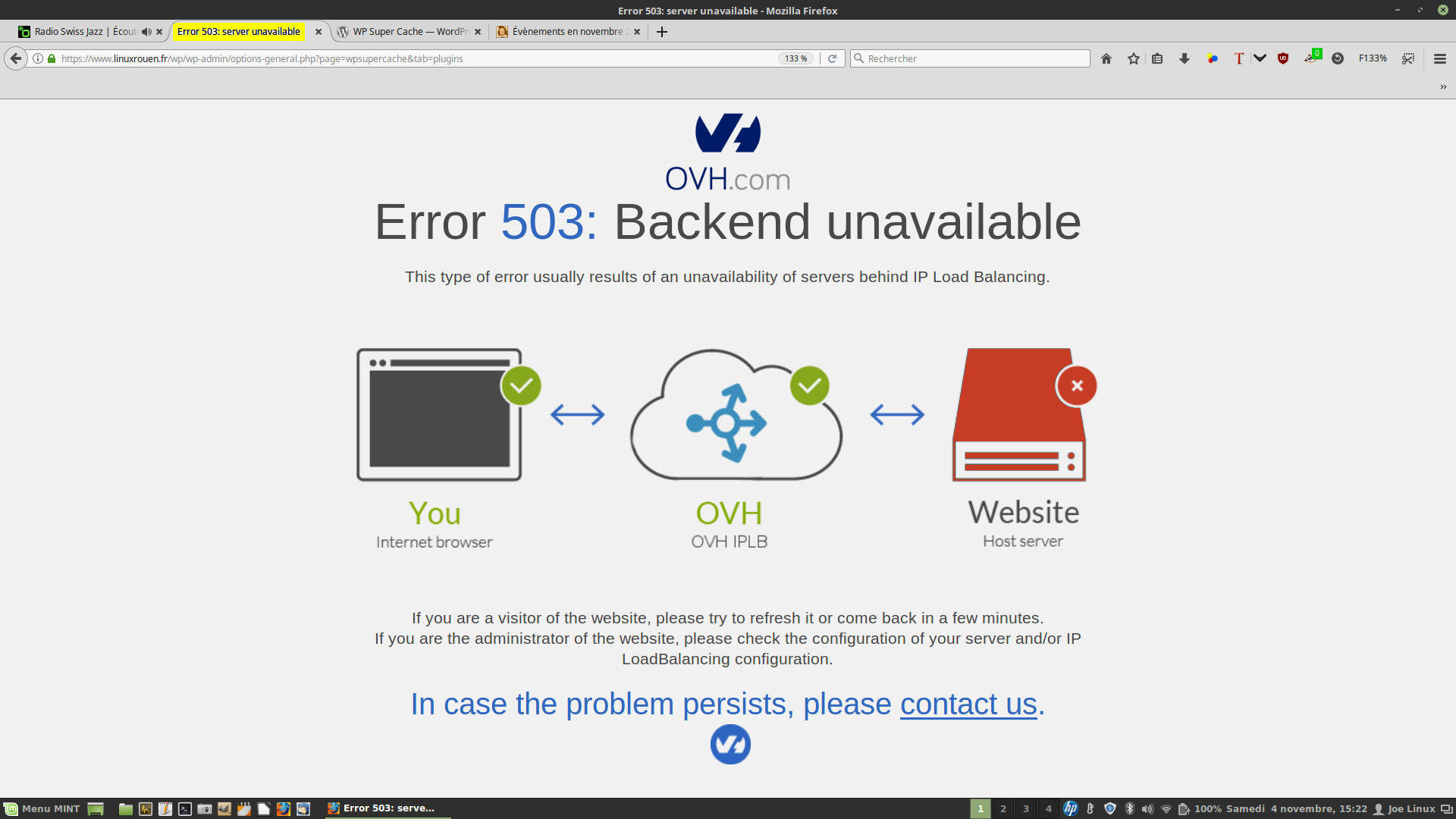
Hébergement mutualisé d’OVH : Malgré qu’OVH a clôturé hier à 19H33 son ticket #28134 les problèmes perdurent !
OVH ne manque pas d’humour quand il recommande : « Si vous êtes l’administrateur du site, merci de vérifier la configuration de votre serveur et/ou la configuration de l’IP LoadBalancing ».
Ce que OVH oublie de dire c’est que pour les hébergements mutualisés l’administrateur du site n’a pas la main sur l’IP LoadBalancing car il n’y a qu’OVH qu’il l’a !
De plus, pour la configuration du serveur, il ne faut surtout pas y toucher car les problèmes mentionnés plus haut dans l’article viennent tous d’OVH. Toucher actuellement à la configuration du serveur serait pire que de ne surtout rien faire !
Nouveau ticket #28150 ouvert par OVH le 4/11/2017 pour P19 / All custers !
FS#28150 | Web Hosting / CloudDB | Incident | P19 / All clusters | Front-end servers | 2017-11-04, 21:47 | In progress | 2017-11-04, 21:47
« Details: We encounter performance issues on our front-end load-balancer since 2017-11-04 05h30 UTC. Our teams are investigating the root cause. »
♦ 5/11/2017 : OVH a écrit
FS#28150 | Front-end servers | Web Hosting / CloudDB | Incident | Category: P19 / All clusters | Status: In progress
Comment by OVH – Sunday, 05 November 2017, 07:39AM
« The infrastructure has stabilized overnight. Cluster005 is no longer impacted by the incident.
In the meantime, we have identified several possibilities to improve the service for the weekend.
A maintenance operation is scheduled on Sunday around 14h (UTC+1) to apply a temporary fix.
All teams are involved in resolving the situation as soon as possible. »
Comment by OVH – Sunday, 05 November 2017, 14:32PM
« Operations in progress, we currently have no ETA. » ! ! !
Comment by OVH – Sunday, 05 November 2017, 16:18PM
« Our operations are still in progress.
We are forced to temporarily disable the SSL certificate deployment process on our front-end servers.
This WILL NOT affect already deployed certificates NOR affect SSL security in any way.
Only the new or renewed certificates will have their deployment delayed. »
Comment by OVH – Sunday, 05 November 2017, 16:40PM
« We have to restart part of our VAC infrastructure in RBX.
All active connections will be interrupted and future traffic is going to be rerouted to the other rack. »
Comment by OVH – Sunday, 05 November 2017, 17:00PM
« We have identified the root cause.
Our web hosting in P19 should now be fully operational.
For now, we’ll keep this ticket open and continue our investigations to fully understand what happened. »
Alors, comme cela OVH aurait enfin identifié la racine du méga-problème mais dont il ne communique pas le détail à ses clients. Par sécurité, OVH garde ouvert le ticket #28150 et va continuer ses investigations pour comprendre complètement ce qui est arrivé.
Alors, OVH a compris ou pas ? Je pense plutôt que OVH et son président – fondateur Octave Klaba continuent de se foutre ouvertement de la tête de leurs clients !
Quand Octave Klaba contredit ses employés ! Alors, où est la vérité ?
- Octave sur Twitter le 5 nov. 2017 à 06:22
« Depuis Vendredi, sur l’hébergement mutu, on se prend de violents DDoS L7. les équipes bossent dessus. On lâche rien. Désolé pour les 503. »
Pourtant tous les serveurs d’OVH sont sensés être protégés par l’Anti-DDoS > La protection anti DDoS par OVH !
Comme quoi les problèmes d’OVH sont toujours et encore bien présents et ses clients sont laissés à l’abandon dans l’épais brouillard roubaisien…
WAIT… WAIT… WAIT… and… SEE…

Hello Octave ! C’est très bien de vouloir bichonner tes employés, mais il ne faudrait pas oublier tes clients qui font vivre ton entreprise OVH en pleine expansion !
Roubaix : chez OVH, un « responsable du bonheur » veille au bien-être des salariés
OVH ferait bien de nommer très rapidement un responsable qui veillera aussi au « bonheur de ses clients » !
- Octave Klaba, ce ch’ti sur lequel (presque) personne ne misait pour rivaliser avec les Gafa – BFMTV le 19/10/2017
« Arrivé à Roubaix à 16 ans sans parler un mot de français, Octave Klaba a créé OVH (pour « On vous héberge » mais aussi son pseudo « Oles Van Herman »), une société qui est l’une des rares en Europe à pouvoir rivaliser avec les services d’hébergement de données de Microsoft, Amazon ou Alibaba… »
♦ 9/11/2017 : Nouvelle Méga-Panne mais cette fois-ci Générale chez OVH, l’entreprise en alerte rouge
Une méga-panne électrique + une super-méga-panne fibre optique chez OVH, fournisseur d’infrastructure Internet, a rendu des millions de sites Web indisponibles pendant plusieurs heures.
Et le docteur Murphy en repasse une nouvelle et double couche !
On dirait que le mauvais œil est sur OVH. Après la méga-panne de son hébergement mutualisé P19 la semaine dernière dans l’après-midi du 3/11 et les jours suivants, même pas une semaine après, c’est au tour de presque l’ensemble des serveurs et services d’OVH d’être impacté par une super-méga-panne générale.
Apparemment deux problèmes majeurs, distincts mais concomitants ont plongé dans le noir les clients d’OVH en déconnectant ce dernier de la toile mondiale
- Panne de fourniture d’alimentation électrique (ERDF) des centres OVH à Strasbourg (SGB), et cerise sur le gâteau, ses propres groupes électrogènes se sont aussi mis en défaut empêchant de réalimenter ses salles de routage.
- Un bogue logiciel chez OVH (ou son prestataire) a entraîné une panne de connexion au réseau optique européen qui interconnecte ses centres de Roubaix (RBX) et de Gravelines (GRA) avec les PoP (point d’accès à Internet).
#OVHDOWN sur Twitter
La situation des incidents « semblerait » se rétablir petit à petit dans la soirée du jeudi 9/11/2017… mais plusieurs milliers de serveurs OVH sont encore et toujours inaccessibles…
Comment by Octave Klaba – Thursday, 09 November 2017, 17:53PM
- Il reste encore en panne, excusez du peu :
- 2.100 serveurs dédiés
- 1.500 instances PCI
- 25.000 VPS
- 300 hosts PCC
♦ 14/11/2017 : OVH semble(rait) avoir fini de régler tous ses problèmes techniques, mais…
Après près d’une semaine de super-méga-galère, certains clients d’OVH ne sont pas du tout, mais alors pas du tout de cet avis !
Et effectivement, en consultant des sites indépendants, par exemple, downdetector.fr, on peut constater qu’entre les déclarations trop optimistes d’Octave Klaba et de sa société OVH, et la vraie réalité vécue sur le terrain encore ce jour par certains de leurs clients, les serveurs et services d’OVH ne sont pas tous UP à nouveau !